

In web backend aspect , queue is very important both frontend and backend web development . Since Drupal provides backend service, we are gonna try on how to handle queue using Drupal API . The reason why queue is very important because it will optimize the usage of server since less resources means less cost. A 4Gb RAM server without Drupal queue API can be achieve with 1Gb RAM with queue . It means some data is temporarily stored on database instead on RAM for operations like installing module . Some modules during installation requires translation to update or sometimes requires dependency. When progress bar is displayed , the Drupal Queue was being used since there are a lot of operations happen at background process. When queue is not develop by Drupal , it will probably display error message of Allowed memory size X bytes exhausted

In this example , the queue was being used for importing contents from csv file. CSV if type of file that stores data that has header and body . The header holds the data as a key and body holds the actual data just like on spreadsheet table,

During the operation ,The row number of csv will be temporary stored on queue for process . It is also possible that the temporary data stored is the actual data from csv per row but this will compromised the server performance .
The first step is fetch the csv file from public folder which is located from {base_path}/sites/default/files/{filename.csv} . This is where default public folder located and can fetch using this code:
$csv_file = fopen(‘public://{filename.csv}’,’r’);
Fetching csv is pretty much easy as long as you know where the csv files is located.
Once the csv was successfully fetched , count the total row and get the header data .
fgetcsv is a function from php that reads file in csv format , it scans all the data from first row until to the last row.
$row = 0;
$header = fgetcsv($csv,10000);
while(fgetcsv($csv,10000)) {
$row++;
}
fclose($csv);
The next step is the main point of article is to show how to hande queue . Drupal provides an API which the data will temporarily stored and processed . The variable should have key ‘operations’ to tell the Drupal that this will be the datas will processed . The operations key requires two arguments which is `$this` and `process` . The `$index` is the current row of the csv where how much row will be process on each iteration. The higher the number the more memory consumes.
$process[‘operations][] = [[$this,’process’],[$index]];
batch_set($process);
The `batch_set()` function is core function from Drupal . This will automatically store data in queue table and execute the batch process . Once the batch_set() function was executed , the loader will display.

On the backend perspective , the javascript will request to server via ajax then the server will process the next queue , once the queues in the table are already finished. It sends signal to browser that the process is gone. This will redirect to the previous page were it started.
public function process($index,&$context) {
if (empty($context['sandbox'])) {
$context['sandbox'] = [];
$context['sandbox']['progress'] = 1;
$context['sandbox']['current_node'] = 0;
$context['sandbox']['max'] = $total_row;
$context['finished'] = FALSE;
}
/* DO LOGIC HERE */
$context['results'][] = 'row # '.($row);
$context['sandbox']['progress']++;
$context['sandbox']['current_node'] = $row;
if ($context['sandbox']['progress'] != $context['sandbox']['max']) {
$context['finished'] = $context['sandbox']['progress'] > $context['sandbox']['max'];
}
}
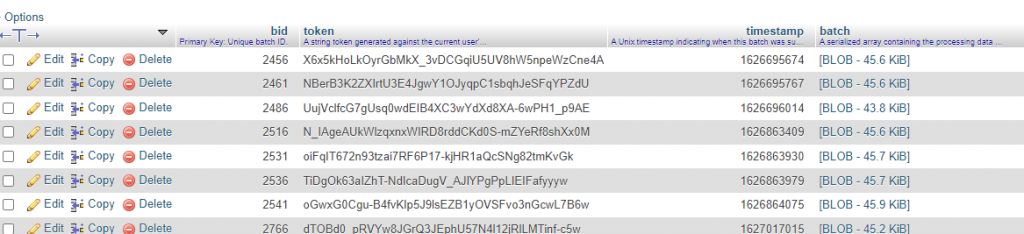
The image above shows as that the queue was created . `bid` column name means batch id , which provide id on each batch process .It can see on the URL itself like `/batch/?id=2456&op=start`.
In conclusion by using Queue , Drupal utilizes the database to minimize the workload on server RAM but the drawback is taking some time to process all the calculations. The main advantage of this implementation is to reduce the risk of server down and the performance is still good.








